Negli archivi digitali dei governi i PDF non sono un residuo del passato: sono la forma con cui si materializza gran parte dell’informazione pubblica. Un progetto come GovScape, sviluppato da ricercatori della University of Washington e della Boston University, rappresenta un cambio di prospettiva. Gli autori hanno preso 10 milioni di documenti PDF provenienti dalla “End of Term Web Archive” del 2020 e li hanno trasformati in un corpus ricercabile, navigabile, interrogabile come se fosse un gigantesco database. È un’operazione che ricorda la bonifica di un territorio: il suolo è lì, vasto e ricco, ma finché non costruisci strade e mappe non puoi davvero attraversarlo.
Come si apprende dal sito Flowing Data, il primo ostacolo è stato tecnico. Un PDF, anche quando contiene testo digitale, non ha una struttura leggibile dalle macchine come accade nei formati pensati per il web. Per un algoritmo è un mosaico di forme che sembrano lettere, ma che non sempre lo sono. La pipeline di GovScape parte da qui: identificare i documenti “trattabili”, estrarre il testo con strumenti di OCR e conversione, costruire un indice che permetta non solo la ricerca per parola chiave ma anche quella semantica, basata sugli embedding, e persino la ricerca visiva, dove ogni pagina diventa un’immagine interrogabile per caratteristiche grafiche. È una forma di riconoscimento che non si limita a leggere cosa c’è scritto, ma osserva come è fatto. Ogni documento è accompagnato inoltre dai metadati raccolti durante il web crawling: il dominio .gov o .mil di origine, la data, il contesto. Questo set di informazioni funziona come la segnaletica stradale di un archivio altrimenti inaccessibile.
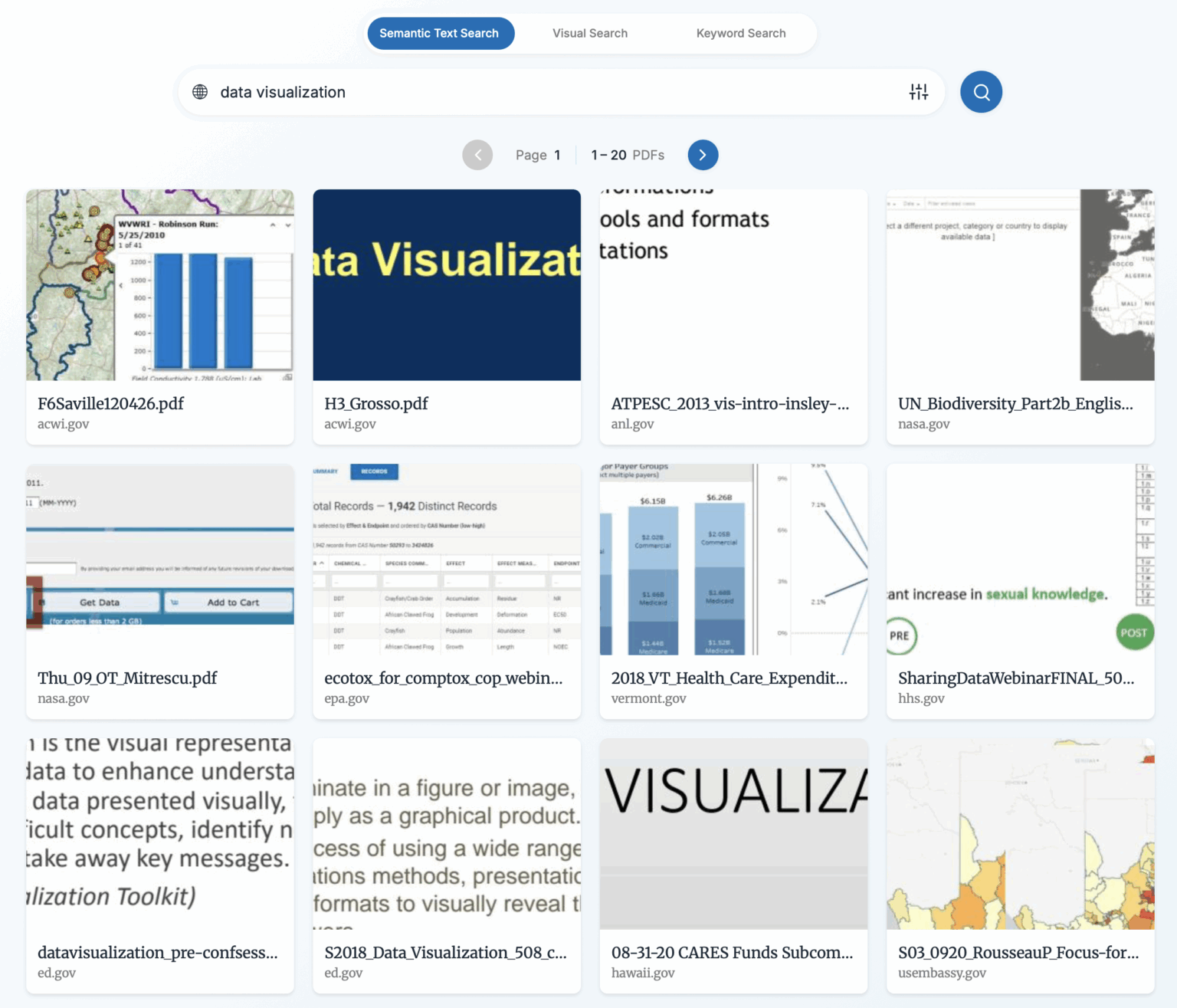
Il risultato è un motore di ricerca pubblico, GovScape.net, che consente a chiunque di esplorare questo patrimonio documentale con query complesse. Si possono cercare concetti, non solo parole; visualizzare pagine con grafici o tabelle; confrontare documenti affini. In totale, il corpus comprende oltre 70 milioni di pagine, secondo il paper tecnico pubblicato su arXiv. È un’infrastruttura che rende telefonabile ciò che prima era silenzioso.
Un dato colpisce più degli altri: l’intero processo di elaborazione è costato circa 1.500 dollari in risorse computazionali. Significa, in pratica, poco più di 47.000 pagine elaborate per ogni dollaro. In un periodo in cui si discute di intelligenza artificiale come se richiedesse sempre potenza illimitata, qui si dimostra l’opposto: con una pipeline ben progettata si ottengono risultati su scala nazionale con un budget da laboratorio universitario. La differenza la fa l’ingegneria dei dati, non la forza bruta.
Progetti di questo tipo non sono isolati. Esiste una genealogia dell’idea di rendere ricercabile ciò che non lo è. Google Books, per esempio, ha usato massicci processi di scansione e OCR per costruire uno dei più grandi archivi testuali del mondo. HathiTrust ha seguito un percorso simile nel mondo accademico. CORE ha indicizzato la letteratura scientifica open access per facilitare la ricerca full-text. Più recentemente, un progetto greco ha estratto e strutturato oltre un milione di decisioni governative da PDF pubblici, dimostrando che queste pipeline non sono più un’eccezione ma un nuovo livello dell’infrastruttura civica digitale.
Per approfondire
La scuola elementare della visualizzazione dei dati. I compiti a casa
La cartografia dell’intelligenza artificiale generativa
Se amate la demografia e la statistica giocate a Dataguessr #MathGamesAndWeirdThings
{kind=link}