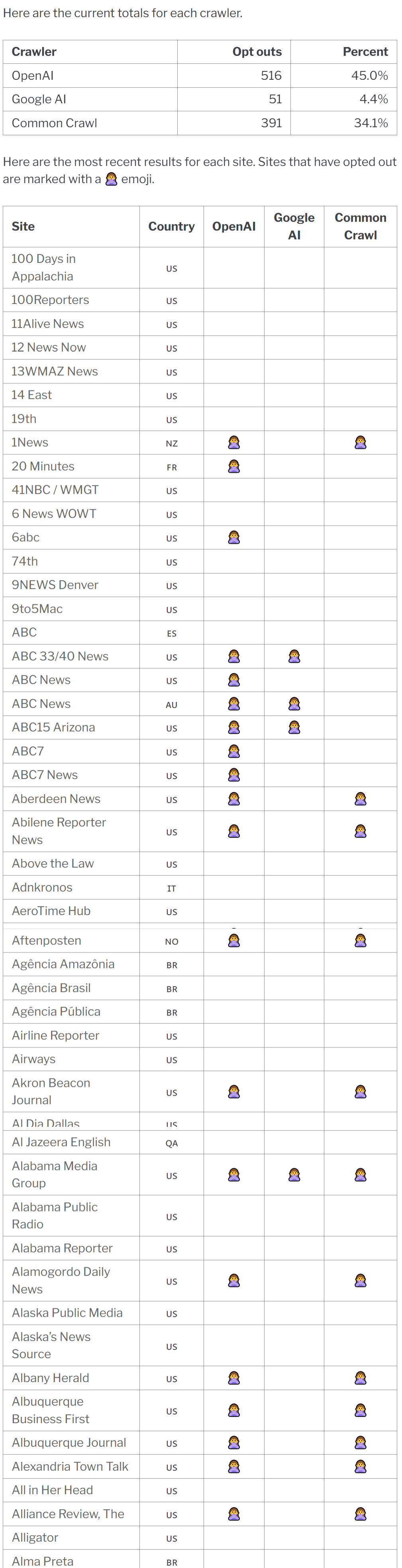
Dopo New York Times, la Cnn e l’agenzia Reuters anche la Bbc ha deciso di bloccare lo scraping dei dati effettuato da OpenAI. La società concessionaria in esclusiva del servizio pubblico radiotelevisivo non vuole che i contenuti pubblicati siano utilizzati per l’addestramento di ChatGpt e altri modelli di intelligenza artificiale generativa. La lista di chi ha detto no all’uso dei propri contenuti ai software di Ai è però ben più lunga. Il giornalista Ben Welsh sta compilando una lista di editori di news che bloccano OpenAI crawlers: In totale, 532 dei 1.147 editori intervistati dall’archivio homepages.news hanno interrotto la scansione dei loro siti, ovvero il 46,4% del campione dsa parte di OpenAI , Google AI o dell’organizzazione no-profit Common Crawl. I tre soggetti in questione scansionano sistematicamente i siti web per raccogliere le informazioni che alimentano chatbot generativi come ChatGPT di OpenAI e Bard di Google .
Il sistema open source gestito da homepages.news raccoglie il file robots.txt di ciascun sito di notizie due volte al giorno. Questa pagina si aggiorna continuamente con gli ultimi risultati.
Una premessa prima di continuare. L’addestramento di modelli linguistici di grandi dimensioni, come quelli di OpenAI e Google, si basa in gran parte sui dati provenienti da Internet. Le implicazioni sul fronte della tutela de copyright di editori e produttori di contenuti digitali e su quello della privacy non sono banali. È possibile regolare la “dieta” di questi chatbot? Si può sapere cosa “mangiano” e quindi da chi stanno prendendo informazioni? Il dibattito è apertissimo.
Per approfondire.
GptBot può essere bloccato? Come regolare l’addestramento sul Web dell’Ai generativa
Cosa sono e a cosa servono i plugin di OpenAi e Microsoft #DatavizAndTools
Python, coding e Gpt-4. Come si programma con l’Ai generativa? #Ascanio

{kind=link}