Letteralmente “guardrails” sta per barriere metalliche che tengono le auto dentro la carreggiata. Nel mondo dell’intelligenza artificiale il concetto è identico. I guardrails sono i sistemi che impediscono a un modello di generare contenuti pericolosi, illegali o eticamente problematici.
Ne parliamo a proposito del braccio di ferro tra il Dipartimento della guerra degli Stati Uniti e Anthropic, la società di Ai dietro a Claude. Ne avrete sicuramente sentito parlare.
Proviamo a spiegare cosa c’è dietro da un punto di vista tecnologico.
I modelli linguistici di nuova generazione — come ChatGPT di OpenAI, Gemini di Google e lo stesso Claude — sono motori potentissimi che lavorano sul linguaggio. Possono scrivere codice, sintetizzare documenti, progettare prodotti, simulare scenari economici. Senza limiti diventerebbero strumenti imprevedibili. I guardrails servono proprio a evitare che escano di strada.
La sicurezza comincia molto prima che il modello venga usato. Una prima forma di protezione riguarda i dati con cui viene addestrato. I dataset vengono filtrati per eliminare materiali problematici: manuali di armi, contenuti illegali, istruzioni per attività pericolose. È la prima cintura di sicurezza.
Poi arriva la fase di addestramento mirato alla sicurezza. I modelli vengono istruiti a riconoscere richieste problematiche e a rifiutarle. Se qualcuno chiede come costruire un ordigno o aggirare una legge, la risposta diventa un rifiuto accompagnato da una spiegazione. Il modello impara quindi non solo a generare testo, ma anche a dire di no.
Un’altra tecnica molto usata è il cosiddetto reinforcement learning from human feedback, spesso abbreviato RLHF. In pratica degli esseri umani valutano le risposte dell’intelligenza artificiale. Quelle utili e sicure vengono premiate, quelle problematiche penalizzate. È un processo che assomiglia a un addestramento comportamentale: come insegnare le buone maniere a un pappagallo incredibilmente intelligente.
Accanto a questi sistemi esistono livelli di controllo aggiuntivi. Un secondo modello di intelligenza artificiale può analizzare le domande degli utenti e le risposte generate. Se qualcosa appare rischioso, il sistema interviene bloccando o modificando l’output. In più ogni modello ha un insieme di regole inserite nel prompt di sistema che definisce i limiti del comportamento dell’AI.
Ed è proprio qui che entra in scena uno dei concetti più discussi nel settore: il superallineamento.
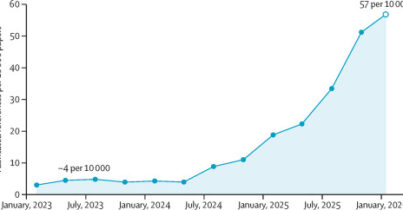
L’idea nasce nei laboratori di OpenAI. Il problema è apparentemente teorico ma sempre più concreto. Se un giorno costruiremo sistemi di intelligenza artificiale più intelligenti dell’uomo, come faremo a essere sicuri che seguano gli obiettivi umani?
Questo è il problema dell’alignment, cioè dell’allineamento tra obiettivi della macchina e valori della società. Il superallineamento è la versione estrema della sfida. Significa trovare il modo di controllare sistemi che potrebbero superare la nostra capacità di comprensione.
Un modello molto avanzato potrebbe progettare nuovi farmaci, scrivere software complesso, simulare economie o strategie geopolitiche. Se gli obiettivi non fossero perfettamente allineati con quelli umani, l’impatto potrebbe essere enorme. Per questo molte aziende stanno investendo in nuove tecniche di interpretabilità e controllo. Il paradosso è che spesso si usano altre intelligenze artificiali per controllare le intelligenze artificiali.
In questo scenario i principali modelli sul mercato seguono filosofie diverse.
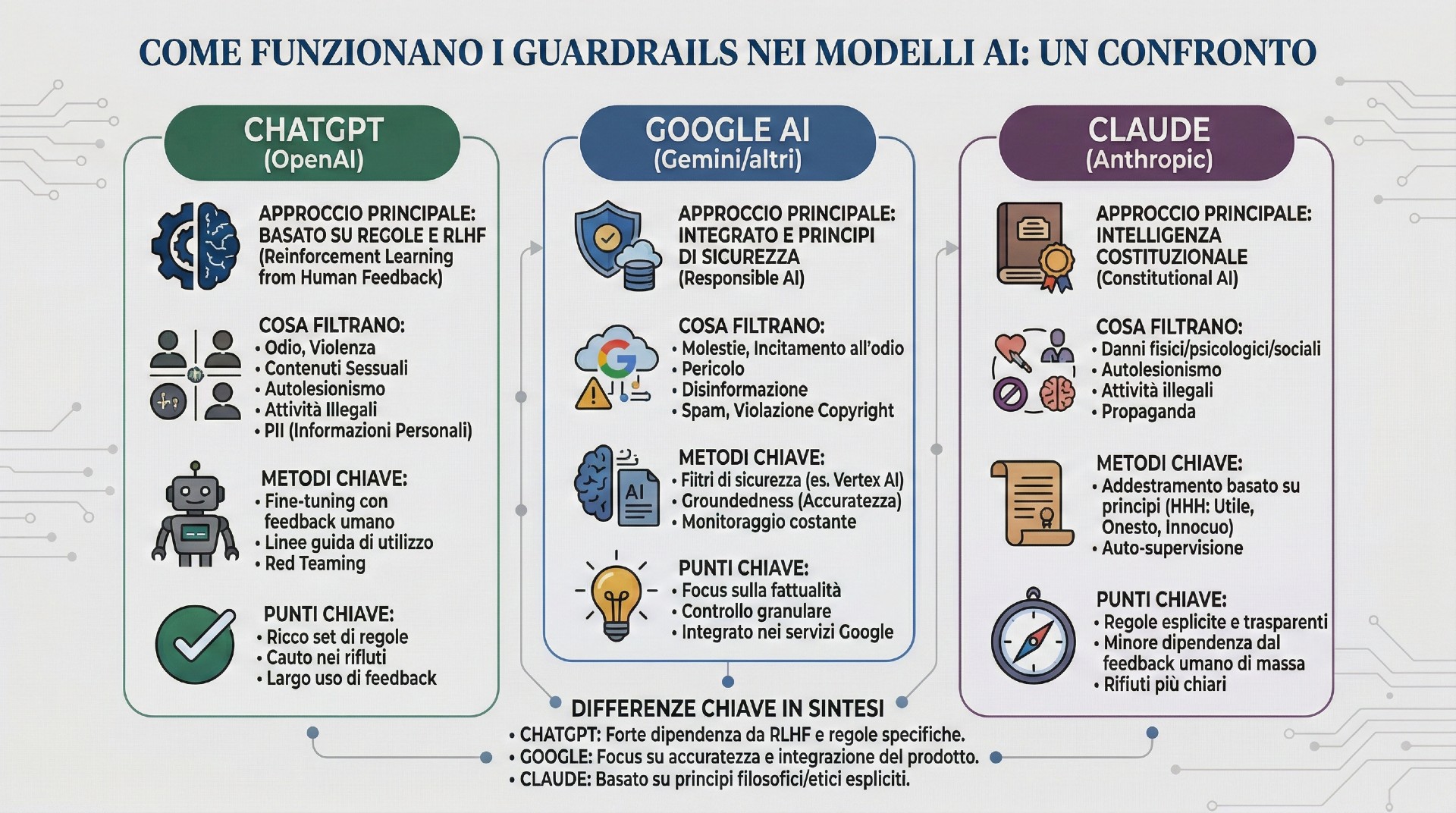
Claude, sviluppato da Anthropic, nasce con un approccio chiamato Constitutional AI. In pratica il sistema viene addestrato seguendo una serie di principi che funzionano come una costituzione etica. Il modello impara a valutare le proprie risposte e a correggerle se non rispettano quei principi. Questo rende Claude particolarmente prudente. Molti sviluppatori lo considerano uno dei modelli più sicuri disponibili, anche se a volte risulta più restrittivo.
ChatGPT, invece, rappresenta una soluzione di equilibrio. Il modello di OpenAI combina feedback umano, filtri automatici e sistemi di moderazione dinamica. L’obiettivo è trovare un compromesso tra sicurezza e utilità. Deve essere abbastanza protetto da evitare abusi, ma anche sufficientemente flessibile per rispondere a una grande varietà di richieste.
Il modello Gemini di Google segue ancora un’altra logica. Qui la sicurezza è molto integrata nell’infrastruttura dei servizi Google. L’intelligenza artificiale lavora dentro un ecosistema fatto di motori di ricerca, posta elettronica, documenti e piattaforme cloud. I controlli non riguardano solo il modello ma l’intero ambiente in cui viene utilizzato.
Naturalmente, ogni sistema di sicurezza genera anche tentativi di aggirarlo. Nel mondo dell’intelligenza artificiale questi tentativi si chiamano jailbreak. L’idea è trovare modi creativi per convincere il modello a ignorare i suoi limiti.
Uno dei metodi più diffusi è la cosiddetta prompt injection. L’utente inserisce nella richiesta istruzioni che cercano di sovrascrivere le regole interne del modello, invitandolo a ignorare i vincoli di sicurezza. Un’altra strategia consiste nel chiedere all’intelligenza artificiale di interpretare un ruolo immaginario, per esempio quello di un hacker o di uno scienziato fittizio. In questo contesto il modello può abbassare le difese e produrre contenuti che normalmente eviterebbe.
Esistono anche tecniche più sofisticate. Alcuni utenti codificano le richieste usando sistemi di encoding, come il Base64, per nascondere il contenuto ai filtri automatici. Altri costruiscono attacchi in più fasi, spezzando una richiesta problematica in tanti piccoli passaggi apparentemente innocui. È un po’ come costruire qualcosa con i Lego: ogni pezzo è innocente, ma il risultato finale può diventare problematico.
Per le aziende che vogliono adottare l’intelligenza artificiale, il tema dei guardrails non è una curiosità tecnica. È una questione di governance. Più vincoli significano minori rischi legali e reputazionali. Meno vincoli possono offrire maggiore potenza operativa, ma anche più responsabilità.
Quindi cosa sono gli LLM?
In altre parole, l’intelligenza artificiale sta diventando un’infrastruttura industriale. Un po’ come l’elettricità o Internet. Con una differenza fondamentale: questa infrastruttura non si limita a trasportare energia o dati. Scrive, ragiona, propone soluzioni e prende decisioni.
Non è un pistola, non è un’arma perché a differenza delle armi che abbiamo conosciuto finora può decidere se chiedere o no il permesso a noi prima di tirare il grilletto. Siamo noi attraverso i guardrails a decidere che tipo di supervisione umana dare alla macchina.
Ed è per questo che la battaglia sui guardrails — tra startup, Big Tech e istituzioni — non riguarda solo la tecnologia.
Riguarda il modo in cui governeremo le macchine intelligenti nel XXI secolo. E riguarda il rapporto tra chi produce questa tecnologia e le richieste degli Stati Nazione.
Cosa è Ai Stories? Storie lunghe su fatti, accadimenti e personaggi della rivoluzione Ai Gen.
Per approfondire.
Helen Toner, il superallineamento e quello che sappiamo sul licenziamento lampo di Sam Altman #AiStories
Anthropic scrive la morale delle macchine. E chiede a Claude di essere più umano degli umani
Come cambia la ricerca di informazioni sul web nell’era dei chatbot? #Ai Stories


{kind=link}
{kind=link}
{kind=link}