Le analisi su questo spinoso problema cominciano a sommarsi. Solo a maggio 2026 ne sono state rese note due molto interessanti perché mostrano che il numero di citazioni false presenti negli studi scientifici pubblicati è un problema in rapida crescita.
Il primo dei due studi è stato pubblicato nientemeno che su The Lancet. L’audit condotto da Maxim Topaz, professore associato alla Columbia School of Nursing e autore principale dello studio, ha passato al vaglio milioni di articoli biomedici pubblicati. Il risultato: oltre 4.000 lavori contenevano citazioni a ricerche inesistenti. Nessuna di queste citazioni false è stata finora ritrattata o corretta, e potrebbero ancora oggi influenzare le decisioni cliniche.
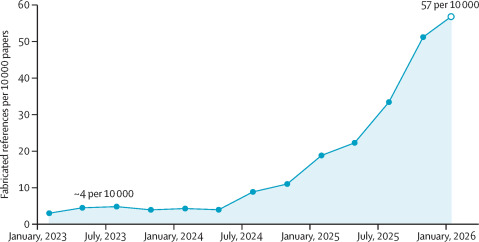
Ciò che preoccupa Topaz non è solo la dimensione attuale del fenomeno, ma la sua traiettoria. Il numero di citazioni false individuate nella letteratura medica pubblicata è cresciuto di dodici volte nel corso degli ultimi tre anni, con riferimenti inventati distribuiti su quasi 3.000 articoli accademici.
Nel 2023, circa un articolo su 2828 conteneva almeno un riferimento falsificato. Nel 2025, questo numero era salito a uno su 458 e nelle prime 7 settimane del 2026, un articolo su 277 presentava almeno un riferimento falsificato. Il tasso di falsificazione è dunque aumentato di oltre 12 volte, passando da circa quattro articoli su 10.000 nel 2023 a 51,3 articoli su 10.000 nel quarto trimestre del 2025, raggiungendo 56,9 articoli su 10.000 all’inizio del 2026.
Un precedente studio pubblicato nel 2023 su Scientific Reports (Nature) aveva già stimato che il 18% delle citazioni di GPT-4, erano inventate.
Le conseguenze pratiche di questa proliferazione sono cruciali. Le linee guida cliniche — i documenti su cui i professionisti sanitari si basano quotidianamente per prendere decisioni terapeutiche — vengono costruite a partire dalla letteratura scientifica pubblicata. Se quella letteratura contiene citazioni a studi mai condotti, il rischio è che affermazioni prive di fondamento reale finiscano per orientare le cure. Come ha spiegato Topaz, il tuo medico potrebbe prendere decisioni sul tuo trattamento basandosi su ricerche che non sono mai esistite.
Come si generano le citazioni fasulle
Le citazioni false non vengono sempre inserite deliberatamente. Il meccanismo più comune, secondo Topaz, è indiretto: un autore afferma un dato di fatto nel testo del proprio articolo e chiede a uno strumento di IA di fornire una citazione a supporto. In alcuni casi il modello ne genera una che sembra perfettamente reale — con nome dell’autore, titolo dello studio, nome della rivista — ma che non corrisponde ad alcuna pubblicazione esistente.
Le modalità possono variare. In certi casi l’IA cita un autore reale, ma gli attribuisce una ricerca mai svolta; in altri, la citazione è interamente inventata, senza alcun aggancio con persone o lavori esistenti. In entrambi i casi, il riferimento può superare diversi livelli di revisione senza essere individuato, perché le citazioni false, come sottolinea Topaz, possono apparire del tutto autentiche.
È una dinamica che lo stesso autore ha vissuto in prima persona. Mentre utilizzava un’applicazione di IA per rifinire un proprio articolo scientifico, il sistema ha inserito autonomamente una citazione falsa nel testo. Quella citazione è poi sopravvissuta a più cicli di revisione tra pari, e solo un editor particolarmente attento l’ha individuata prima della pubblicazione.
Una conferma
Un’altra analisi, condotta da un gruppo di ricercatori della Cornell University, ha misurato per la prima volta su larga scala il fenomeno delle citazioni bibliografiche “allucinate” — riferimenti a studi o autori che non esistono, generati automaticamente dai modelli linguistici di intelligenza artificiale. I numeri sono di un’entità difficile da ignorare.
Lo studio, pubblicato come preprint su arXiv e non ancora sottoposto a revisione tra pari, ha esaminato 2,5 milioni di articoli e preprint per un totale di 111 milioni di riferimenti bibliografici, attingendo ai principali archivi scientifici internazionali: arXiv, bioRxiv, SSRN e PubMed Central. Il risultato: nel solo 2025, fino al mese di agosto, sono state individuate 146.932 citazioni inventate.
I ricercatori hanno stabilito come soglia di partenza il 2022 — anno del lancio di ChatGPT, il primo grande modello linguistico accessibile al pubblico — per distinguere le allucinazioni dagli errori bibliografici di altra natura, preesistenti all’era dell’IA generativa. I riferimenti sospetti sono stati verificati incrociando i titoli con tre grandi database accademici: Semantic Scholar, OpenAlex e Google Scholar.
Il dato che emerge con più forza riguarda la distribuzione del fenomeno tra le diverse piattaforme. SSRN, il principale archivio di preprint in scienze sociali ed economiche, registra un tasso del 1,91% di citazioni allucinate — quasi cinque volte superiore a qualsiasi altro repository considerato. arXiv, dedicato prevalentemente alle scienze fisiche, segue con lo 0,39%. PubMed Central, che raccoglie pubblicazioni biomediche sottoposte a peer review, si attesta allo 0,27%, mentre bioRxiv, preprint server per le scienze biologiche, chiude con lo 0,21%.
Alcune tendenze
Lo studio rileva anche alcune tendenze qualitative: le citazioni false compaiono con maggiore frequenza nei lavori firmati da autori con una storia pubblicativa limitata prima del 2022, e tendono ad attribuire i lavori inventati ad accademici già affermati, molto citati e prevalentemente di genere maschile.
Il confronto diretto tra repository richiede cautela, per ragioni metodologiche che il preprint stesso riconosce. SSRN ospita preprint e working paper sottoposti a controlli minimi prima della pubblicazione, mentre PubMed Central include articoli che hanno superato la revisione tra pari: parte del divario osservato potrebbe riflettere differenze nel rigore editoriale più che caratteristiche intrinseche delle singole discipline.
I sistemi di repository, dal canto loro, stanno adottando misure diverse per fronteggiare il problema: arXiv ha inasprito le proprie politiche di accreditamento all’inizio del 2025, bioRxiv dispone di processi di screening, mentre SSRN richiede agli autori una dichiarazione esplicita sull’uso dell’IA.
{kind=link}