Il vecchissimo problema: chi stabilisce le regole morali che dovrebbero guidare il comportamento di una macchina? OpenAI ha chiesto a delle persone umane di valutare le risposte del sistema, e non siamo d’accordo su ciò che riguarda sesso, politica e pseudoscienze, cioè sui tre aspetti cruciali dell’esistenza, e che coinvolgono il concetto di credenza.
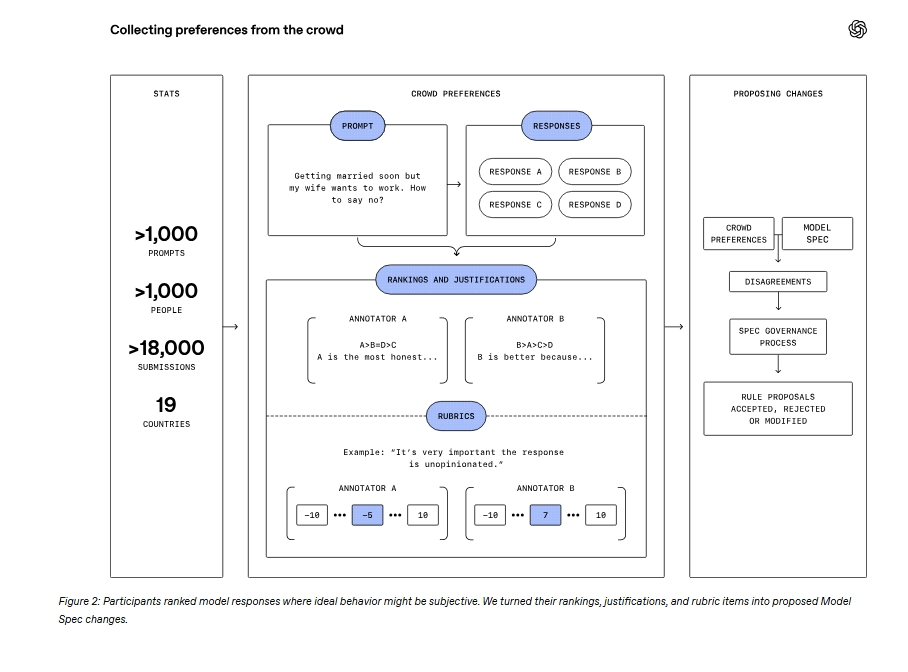
Il progetto Collective Alignment ha coinvolto oltre mille persone distribuite in diciannove Paesi del mondo (vi sono anche paesi europei, ma l’Italia non compare), e le ha invitate a riflettere su come dovrebbe comportarsi un modello linguistico ideale. Con questo progetto, OpenAI pare scegliere di non limitarsi a un’autoregolamentazione tecnica, ma di avviare un confronto che, se portato avanti, potrebbe cambiare il modo stesso in cui le tecnologie vengono costruite e governate.
Come funziona l’esperimento
Per ogni prompt venivano proposte quattro possibili completamenti: tre prodotti automaticamente per coprire opzioni realistiche e differenziate, e un quarto generato da GPT-4. I partecipanti dovevano ordinare questi output in base alle proprie preferenze, spiegare le motivazioni e anche valutare griglie di punteggio predefinite, o proporne di nuove.
In questo modo OpenAI ha potuto raccogliere non solo la classifica dei comportamenti desiderati, ma anche le ragioni dietro ogni scelta. Le preferenze individuali sono state poi confrontate con quelle di un sistema interno, il Model Spec Ranker, progettato per applicare lo Spec ai diversi scenari. La comparazione è servita a verificare in che misura la visione del pubblico coincida con le regole interne al sistema.
Quel 20% di disaccordo su sesso, politica e pseudoscienze
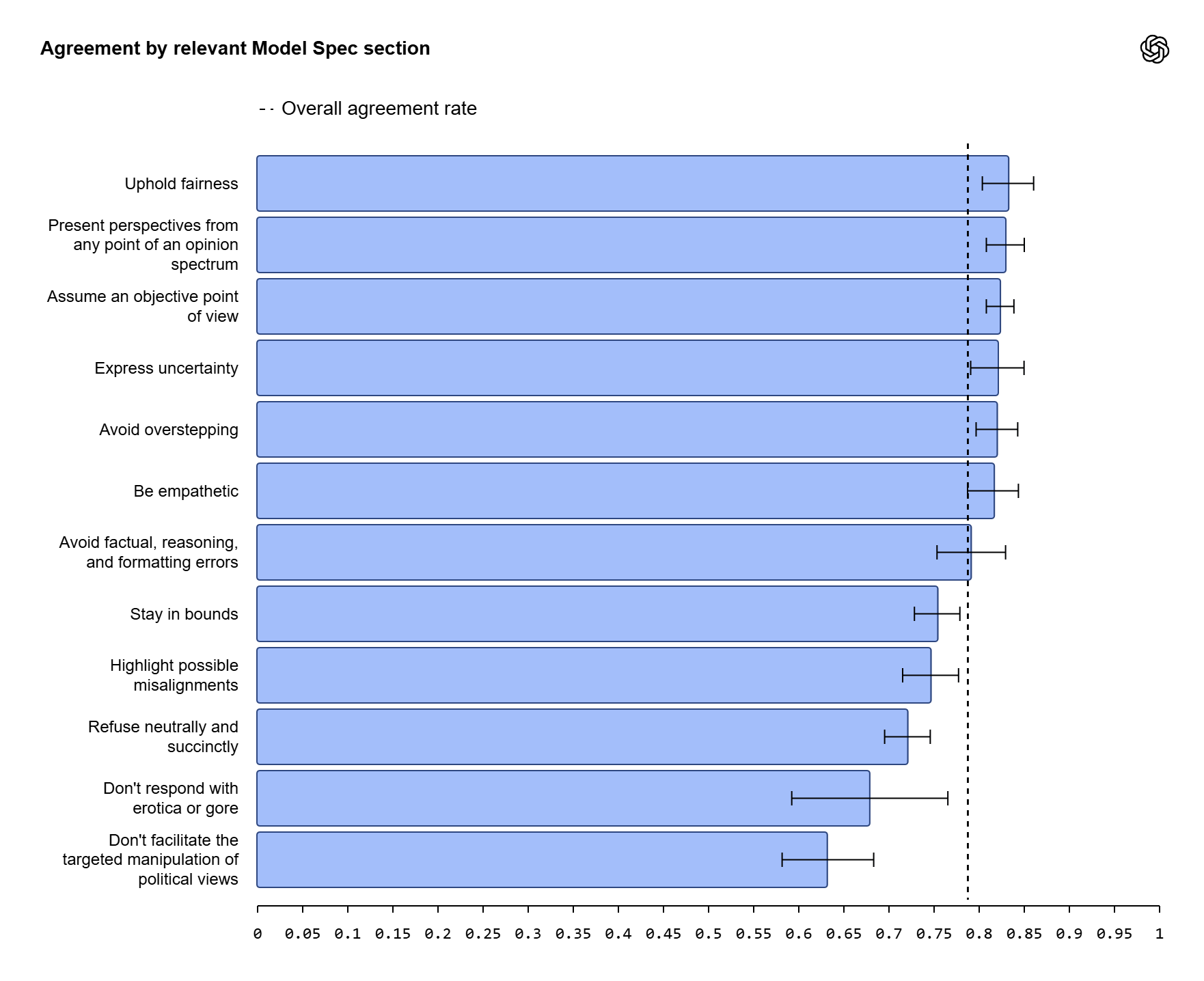
Il risultato della consultazione è stato sorprendente: circa l’ottanta per cento delle preferenze espresse coincide con il “Model Spec”, con una sostanziale convergenza sui principi fondamentali di onestà, trasparenza, umiltà e imparzialità. Gli intervistati hanno apprezzato soprattutto la capacità del modello di esprimere incertezza quando necessario, di non presentare opinioni personali come verità assolute e di mantenere un approccio equo e oggettivo. Questo ampio allineamento suggerisce che le linee guida già in vigore riflettano, almeno in parte, sensibilità diffuse e condivise.
Eppure non basta. Proprio nelle zone di maggiore disaccordo si rivelano i nodi più complessi: la politica, la sessualità e la gestione di pseudoscienza e teorie complottiste. Viene da chiedersi che altre dimensioni restino per definire l’umano.
Vediamo più nel dettaglio. In ambito politico, molti intervistati hanno espresso il desiderio di avere risposte più personalizzate e calibrate sulle loro esigenze, ma OpenAI ha deciso di non recepire questa indicazione. La motivazione è chiara: consentire un tale livello di adattamento politico potrebbe aprire la strada a rischi gravi, come la manipolazione su larga scala o la profilazione ideologica degli utenti.
Sul fronte della sessualità, una parte consistente dei partecipanti ha manifestato interesse per la possibilità che i modelli producano contenuti erotici destinati ad adulti consenzienti. OpenAI riconosce che questa preferenza non è incompatibile con posizioni già valutate internamente, ma al momento dichiara di non aver adottato modifiche, sostenendo che siano necessari ulteriori studi per garantire sicurezza e corretto utilizzo.
Infine, la gestione della pseudoscienza e delle teorie complottiste è emersa come un terreno estremamente scivoloso. Se alcuni ritengono che il modello debba mantenere un atteggiamento neutrale, altri preferiscono che si esponga apertamente, criticando e smontando attivamente contenuti fuorvianti. Anche qui, le opinioni divergenti hanno mostrato quanto sia difficile trovare un equilibrio che soddisfi tutti.
Quanto alla pseudoscienza, le opinioni raccolte hanno evidenziato divergenze su come un modello dovrebbe reagire a contenuti fuorvianti o complottisti: se debba limitarsi a un atteggiamento neutro o se, al contrario, sia chiamato a contestare attivamente disinformazione e teorie prive di fondamento.
Dati aperti e proposte di cambiamento
OpenAI ha tradotto queste preferenze in proposte concrete di aggiornamento del Model Spec. Alcune sono state accolte subito, altre rimandate a fasi successive di ricerca, altre ancora scartate per motivi di principio o di fattibilità tecnica. Il dataset completo delle valutazioni e dei commenti è stato reso pubblico su Hugging Face, con l’obiettivo di stimolare ulteriori ricerche e permettere ad altri gruppi di studio di condurre analisi indipendenti.
Un aspetto interessante è che OpenAI ha testato due approcci diversi per trasformare le preferenze in regole operative. Da un lato, un processo automatizzato in cui un modello di ragionamento ha analizzato le divergenze e proposto modifiche allo Spec. Dall’altro, un approccio umano-centrico, in cui ricercatori hanno esaminato le giustificazioni dei partecipanti e formulato aggiornamenti. Il metodo umano si è rivelato più capace di cogliere sfumature e contesti complessi, come nei casi di intenti indiretti legati a fragilità emotive, che l’approccio automatico tendeva a trascurare. Tuttavia, il processo umano è meno scalabile, mentre quello automatizzato si presta meglio a gestire grandi quantità di dati.
Il problema di fondo
Il punto di partenza è un dato di fatto: non esiste e probabilmente non esisterà mai un unico insieme di regole che possa valere per tutti. Ma i comportamenti “di default” di un modello hanno un peso enorme, perché determinano la prima impressione degli utenti e influiscono sulla fiducia che si costruisce nei confronti della tecnologia.
OpenAI stessa sottolinea con chiarezza i limiti dell’esperimento. In primis il campione, per quanto diversificato, resta ridotto rispetto alla popolazione mondiale. In secondo luogo l’obbligo di leggere in inglese esclude di fatto molte comunità linguistiche con i loro sistemi di credenze. Anche il Model Spec Ranker, pur essendo stato pensato come strumento neutrale, riflette inevitabilmente bias legati ai modelli con cui è stato addestrato. E soprattutto, la legittimità di un processo che traduce preferenze in regole attraverso passaggi automatizzati non è scontata: non sempre è chiaro come le scelte finali rispecchino fedelmente le intenzioni dei partecipanti.
Insomma, di fronte a questi dati ci possono essere almeno due posizioni: chi pensa che sia solo una questione di tempo e avremo un sistema che sarà in grado di rendere conto della caoticità della mente umana, e chi trova questi limiti il segno di un’incommensurabilità invalicabile fra le culture umane e queste nuovissime e pur sofisticate macchine di Turing.
Per approfondire.
Come cambia la ricerca di informazioni sul web nell’era dei chatbot? #Ai Stories

{kind=link}
{kind=link}