Microsoft porta il suo multi-modello fuori dai laboratori e dentro il lavoro quotidiano. Con i nuovi aggiornamenti di Researcher, l’agente di deep research di Microsoft 365 Copilot, l’idea non è più affidarsi a un solo grande modello, ma far collaborare modelli diversi con ruoli distinti: uno produce, un altro critica, altri ancora mettono a confronto approcci e risultati. È un passaggio importante perché traduce in prodotto una tesi che da mesi circola nell’AI: per i compiti complessi non basta un modello potente, serve un sistema. E Microsoft ora prova a dimostrarlo con due novità precise — Critique e Council — e con un’estensione di Copilot Cowork nel programma Frontier, cioè la corsia in cui l’azienda rende disponibili in anteprima le capacità più avanzate del suo Copilot. Secondo Microsoft, i risultati si vedono anche nei benchmark: Researcher con Critique ottiene un punteggio superiore del 13,8% nel benchmark DRACO rispetto al miglior sistema riportato nel paper di riferimento, e migliora in modo significativo rispetto alla versione single-model di Researcher. Ma vediamo in cinque punti quello che sappiamo finora.
New in M365 Copilot: Council.
You can run multiple models on the same prompt at the same time, so you can see where they align and diverge, and understand what each adds. pic.twitter.com/2p7O14OLFp
— Satya Nadella (@satyanadella) March 30, 2026
Microsoft scommette sul “multi-model intelligence”
Nel post dedicato a Researcher, Microsoft presenta esplicitamente questa architettura come “multi-model intelligence”, mentre nel post su Copilot Cowork viene ribadito che Microsoft 365 Copilot è costruito su un “multi-model advantage”, cioè sulla capacità di portare nel tenant aziendale il meglio di modelli e laboratori diversi. Significa che Microsoft vuole trasformare la varietà dei modelli in una caratteristica del prodotto enterprise.
Critique separa generazione e valutazione
La novità più rilevante è Critique. Qui Microsoft divide il lavoro in due fasi: un modello pianifica il task, recupera le informazioni e prepara una prima bozza; un secondo modello interviene come revisore esperto per rafforzare struttura, completezza, affidabilità delle fonti e rigore delle citazioni. Microsoft spiega che i modelli coinvolti arrivano dai Frontier labs, inclusi Anthropic e OpenAI. L’idea è non chiedere a un solo modello di fare tutto, ma assegnare a uno il compito di scrivere e a un altro quello di criticare. È una logica molto vicina ai processi di revisione accademica e professionale, che infatti Microsoft richiama esplicitamente.
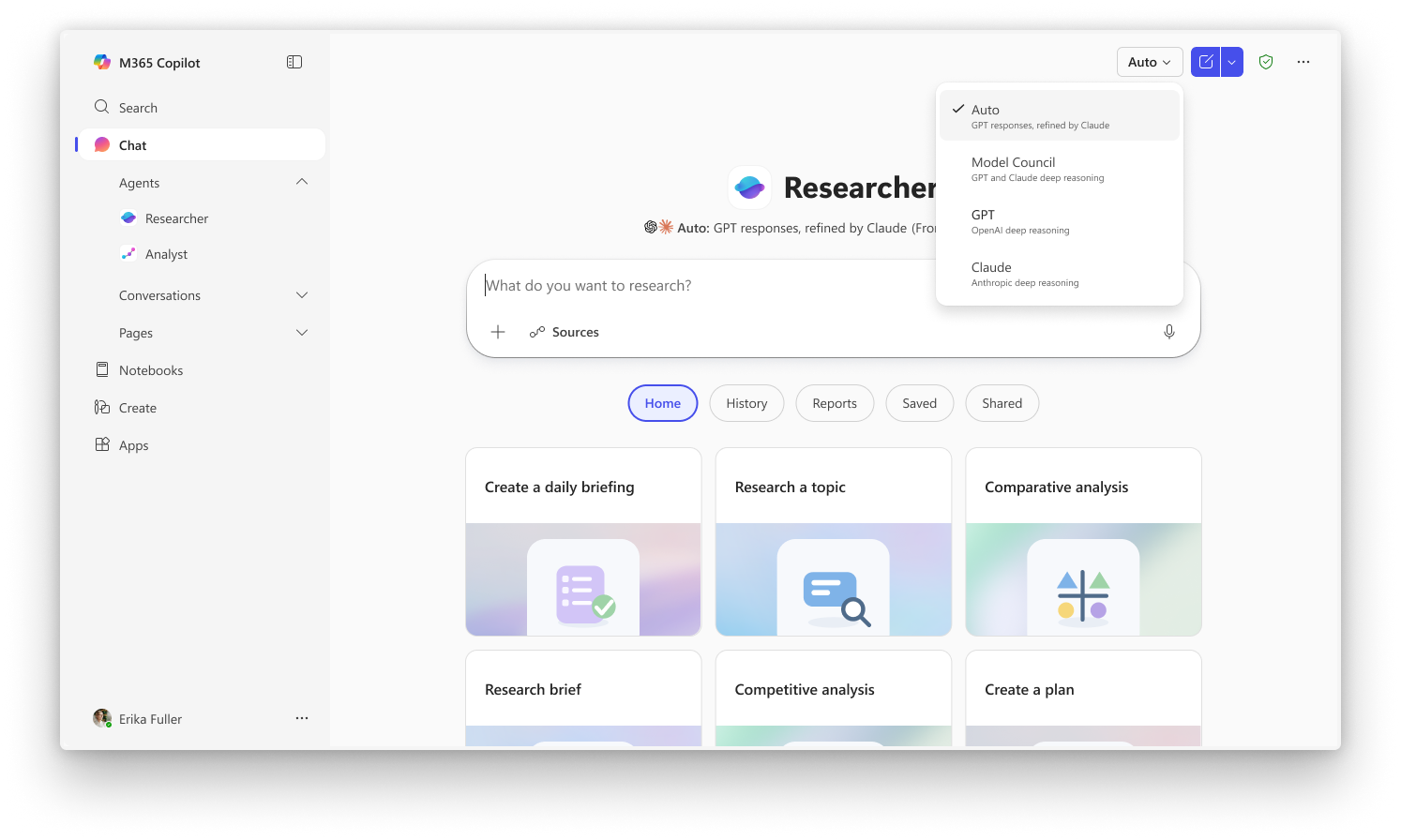
Council mette i modelli uno accanto all’altro
Se Critique punta alla revisione, Council punta al confronto. In questo caso Researcher esegue in parallelo un modello di Anthropic e uno di OpenAI, ciascuno dei quali produce un report completo e autonomo. Poi un ulteriore modello giudice sintetizza i risultati, evidenziando dove i due sistemi convergono, dove divergono e quali contributi originali porta ciascuno. Microsoft descrive Council come un modo per avere “più ricercatori a portata di mano”: non una sola risposta finale, ma una comparazione strutturata di prospettive, pesi interpretativi e fonti. È un passaggio interessante perché trasforma la differenza fra modelli da problema da nascondere a informazione utile da mostrare all’utente.
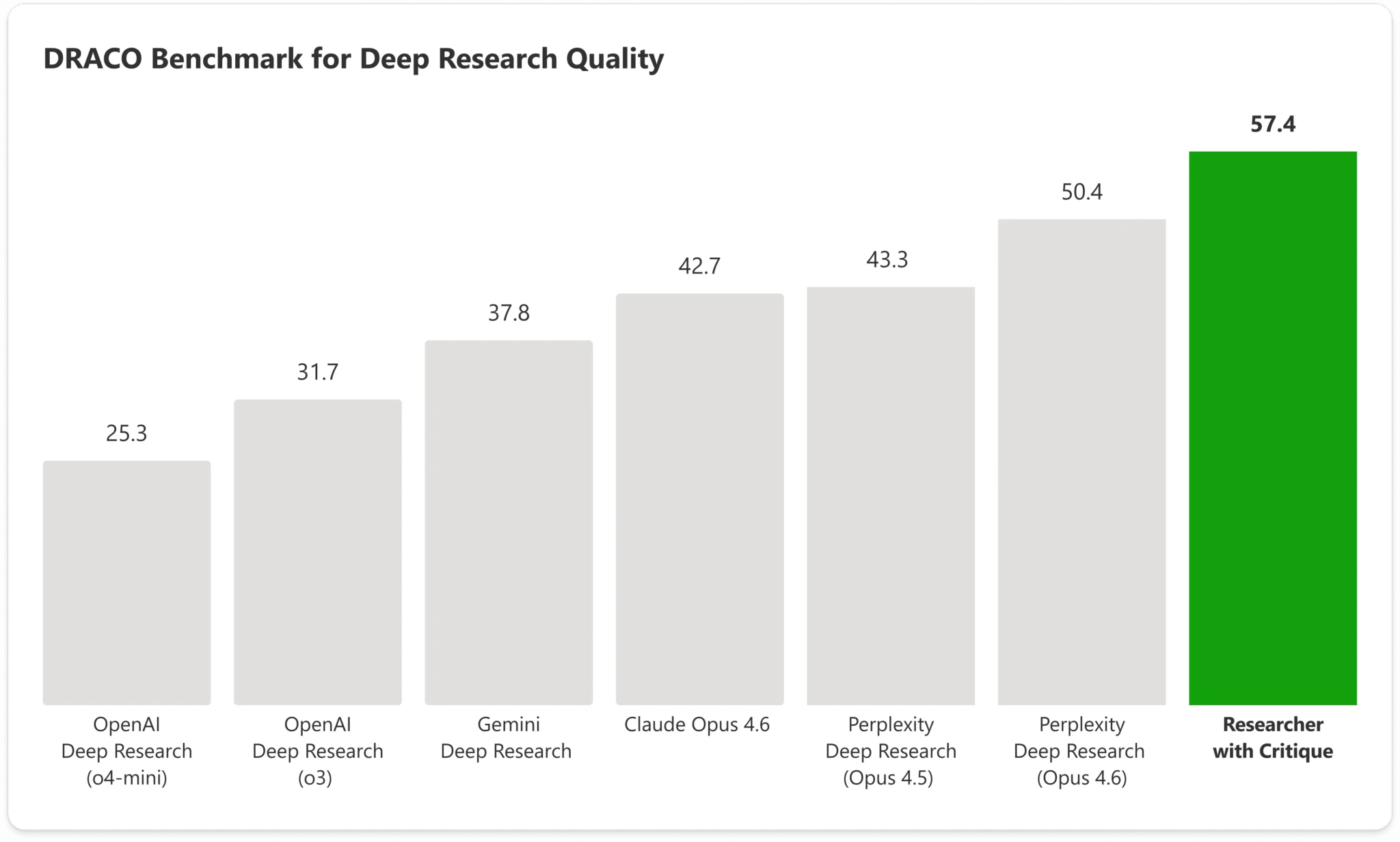
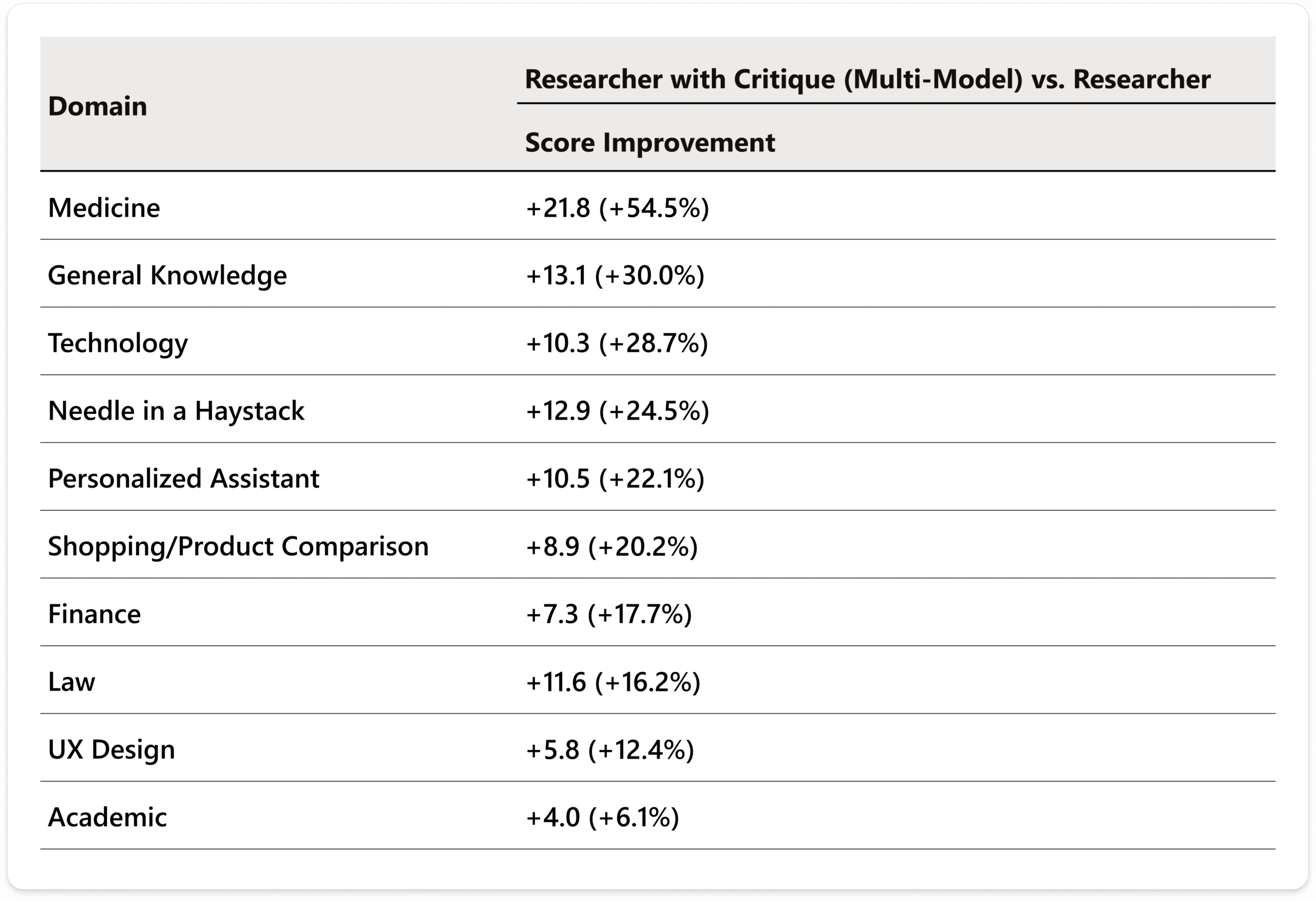
I benchmark servono a dare sostanza al racconto
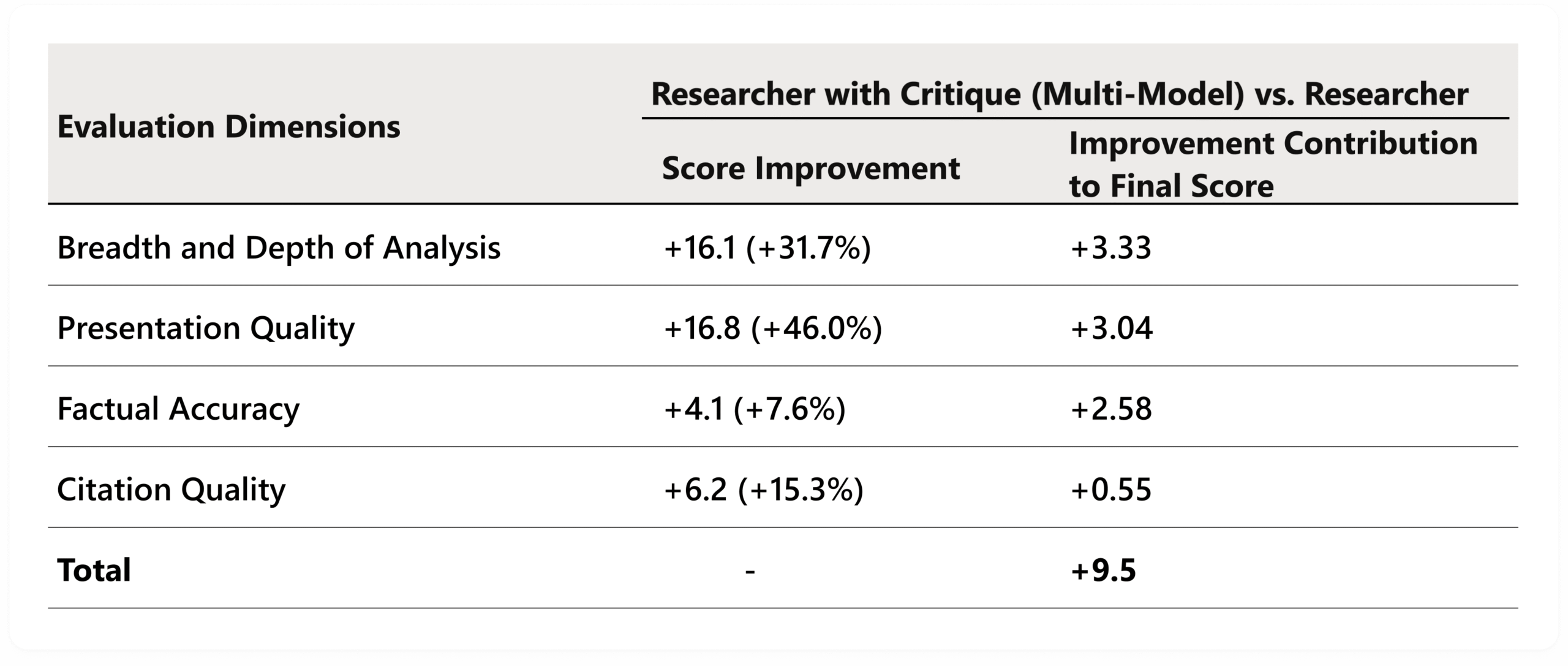
Microsoft accompagna l’annuncio con numeri precisi. Nel benchmark DRACO — acronimo di Deep Research Accuracy, Completeness, and Objectivity — Researcher con Critique ottiene un punteggio aggregato di 57,4, contro 50,4 del miglior sistema riportato nel paper, cioè Perplexity Deep Research, con un miglioramento dichiarato del 13,88%. Nel confronto interno con il Researcher single-model, Microsoft segnala miglioramenti statisticamente significativi su accuratezza fattuale, ampiezza e profondità dell’analisi, qualità della presentazione e qualità delle citazioni. Il benchmark DRACO, pubblicato su arXiv nel febbraio 2026, è costruito su 100 task complessi di deep research in 10 domini e valuta gli output su quattro dimensioni: accuratezza, breadth/depth, presentazione e citazioni. Detto altrimenti: Microsoft prova a sostenere con una misura esterna l’idea che la cooperazione tra modelli renda la ricerca migliore.
Cowork allarga il discorso: dall’analisi all’azione
L’altro tassello è Copilot Cowork, ora disponibile attraverso il programma Frontier. Qui Microsoft sposta il focus dalla ricerca alla capacità di eseguire lavori lunghi e multi-step dentro Microsoft 365. Cowork, spiega l’azienda, permette di descrivere un risultato desiderato, lasciare che il sistema costruisca un piano, ragioni su file e strumenti e porti avanti il lavoro mostrando lo stato di avanzamento e lasciando spazio all’intervento dell’utente. Con competenze derivate da Claude e da Microsoft, Cowork può gestire sia task singoli sia workflow ripetibili, come una revisione mensile del budget. Messo insieme con Researcher, il quadro diventa più ampio: il multi-modello non serve solo a scrivere report migliori, ma a costruire agenti capaci di ragionare, confrontarsi e poi agire nei flussi di lavoro aziendali.
Per approfondire.
Cosa cambia con Copilot Cowork di Microsoft?
Tutte le novità di Microsoft Ignite in dieci punti
Copilot diventa più umano? Le 12 novità di Microsoft AI spiegate in cinque punti
Windows 11 entra nell’era dell’AI: in cinque punti il nuovo “PC agente” di Microsoft
Microsoft Copilot ora è su tutti gli smartphone. #DatavizAndTools
Cosa dobbiamo sapere di Microsoft Build 2025? In cinque punti
Copilot Vision analizza i siti e la navigazione via web #DatavizAndTools
Microsoft ha aggiornato Copilot. Ecco come si è evoluto
Le novità di Microsoft Copilot, il servizi Daily e quello che dobbiamo sapere di Recall
re domande sul Festival di Sanremo a Microsoft CoPilot #PromptAnalysis
Come funziona (e quanto costa) Copilot Pro? #DatavizAndTools
Microsoft Copilot ora è su tutti gli smartphone. #DatavizAndTools


{kind=link}
{kind=link}
{kind=link}
{kind=link}