Il 26 dicembre 2025 è uscito sulla prestigiosa rivista scientifica Nature Digital Medicine un articolo dal titolo di per sé poco intrigante e che non è stato ripreso praticamente da nessuno: A novel evaluation benchmark for medical LLMs illuminating safety and effectiveness in clinical domains. Se non fosse che gli autori sono un team di un’azienda cinese – Future Doctor – che ha presentato il primo quadro standardizzato al mondo per valutare l’applicabilità clinica dei sistemi di intelligenza artificiale in medicina.
Il lavoro è interessantissimo perché se attualmente sono i colossi americani a dettare il passo al momento, è la prima volta che un team di una startup cinese pubblica su una rivista internazionale di primo piano standard di benchmark per i large language model in ambito sanitario.
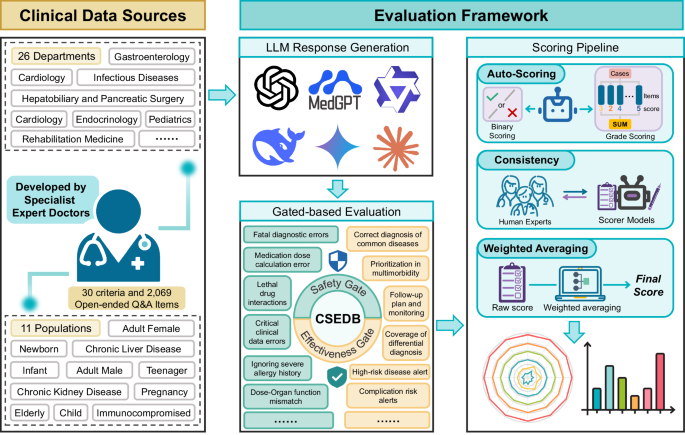
I modelli linguistici di grandi dimensioni (LLM) sono promettenti nel supporto alle decisioni cliniche, ma devono affrontare importanti sfide nella valutazione della sicurezza e nella convalida dell’efficacia. Lo studio introduce il Clinical Safety-Effectiveness Dual-Track Benchmark (CSEDB), un sistema di valutazione pensato per misurare in modo realistico come i modelli di IA si comportano negli scenari clinici reali. Il CSEDB è stato elaborato congiuntamente dal team di Future Doctor e da 32 esperti clinici di 23 istituzioni mediche di vertice in Cina, tra cui il Peking Union Medical College Hospital, il Cancer Hospital dell’Accademia cinese delle scienze mediche, il Chinese PLA General Hospital e l’ospedale Huashan affiliato alla Fudan University.
Il disclaimer di Nature
Ma un aspetto altrettanto interessante è che Nature ha apposto un disclaimer in cima all’articolo. Dice: “Stiamo fornendo una versione non revisionata di questo manoscritto per consentire un accesso anticipato ai risultati. Prima della pubblicazione definitiva, il manoscritto sarà sottoposto a ulteriori revisioni. Si prega di notare che potrebbero essere presenti errori che incidono sul contenuto e si applicano tutte le esclusioni di responsabilità legali.” Anche una rivista come Nature ha dunque deciso di pubblicare il lavoro (che era su BiorXiv dal 31 luglio 2025) nonostante ammetta che la peer review non è completa. Si noti comunque che gli autori hanno inviato il lavoro a Nature ad agosto ed è stato reso pubblico solo a fine dicembre. Insomma, pare che la valutazione abbia preso mesi.
Dato che l’articolo è stato pubblicato, un effetto sul mercato lo porta e va raccontato.
Inoltre, tutti i materiali supplementari e le tabelle contenute nell’appendice sono resi pubblicamente accessibili nel repository ufficiale del progetto su GitHub. Nello stesso archivio è disponibile anche l’intero codice utilizzato per riprodurre le analisi, permettendo alla comunità scientifica di verificare i risultati, testare il benchmark CSEDB e riutilizzare gli strumenti sviluppati dal team di ricerca.
Chi è Future Doctor e che cosa fa MedGPT
Future Doctor è una delle principali aziende al mondo nel settore dell’intelligenza artificiale applicata alla medicina. Nasce all’interno del Medlinker Group, fondato nel 2014. Il cuore della strategia dell’azienda è MedGPT, un grande modello linguistico verticale dedicato alla medicina. Si tratta del primo algoritmo di intelligenza artificiale generativa approvato a livello nazionale in Cina per fornire suggerimenti su diagnosi e trattamenti delle malattie. Il sistema si basa su un’enorme quantità di dati clinici di alta qualità e utilizza l’IA per ampliare su larga scala le competenze dei medici esperti.
MedGPT è stato progettato per accompagnare l’utente in ogni fase del percorso sanitario – prevenzione, diagnosi, trattamento e riabilitazione – con l’obiettivo di offrire un supporto tecnologico concreto alla visione dichiarata dall’azienda: “estendere di un anno l’aspettativa di vita in salute di tutta l’umanità”.
I numeri attuali danno la misura della diffusione raggiunta: la piattaforma ha già oltre 20 milioni di utenti registrati e più di 1,5 milioni di medici iscritti, risultati che hanno attirato il riconoscimento e il sostegno di numerosi investitori istituzionali di primo piano.
In che modo questo approccio sarebbe diverso
La creazione del CSEDB affonta un tema delicatissimo: la valutazione globale delle capacità cliniche dell’IA medica, offre una direzione per il miglioramento iterativo dei modelli linguistici. Il nuovo standard introduce per la prima volta a livello globale un sistema a doppio binario che misura sia la sicurezza sia l’efficacia, allineandosi pienamente ai processi decisionali reali.
La metodologia abbandona i test statici e utilizza 2.069 scenari clinici aperti distribuiti su 26 specialità mediche, progettati per simulare la complessità delle decisioni reali. La valutazione comprende 30 indicatori chiave: 17 relativi alla sicurezza – come il riconoscimento di condizioni critiche, errori diagnostici fatali, farmaci assolutamente controindicati e sicurezza terapeutica – e 13 sull’efficacia, tra cui l’aderenza alle linee guida e l’ottimizzazione dei percorsi diagnostici e terapeutici. Ogni indicatore è ponderato da 1 a 5 in base al rischio clinico, dove 5 corrisponde a scenari potenzialmente letali.
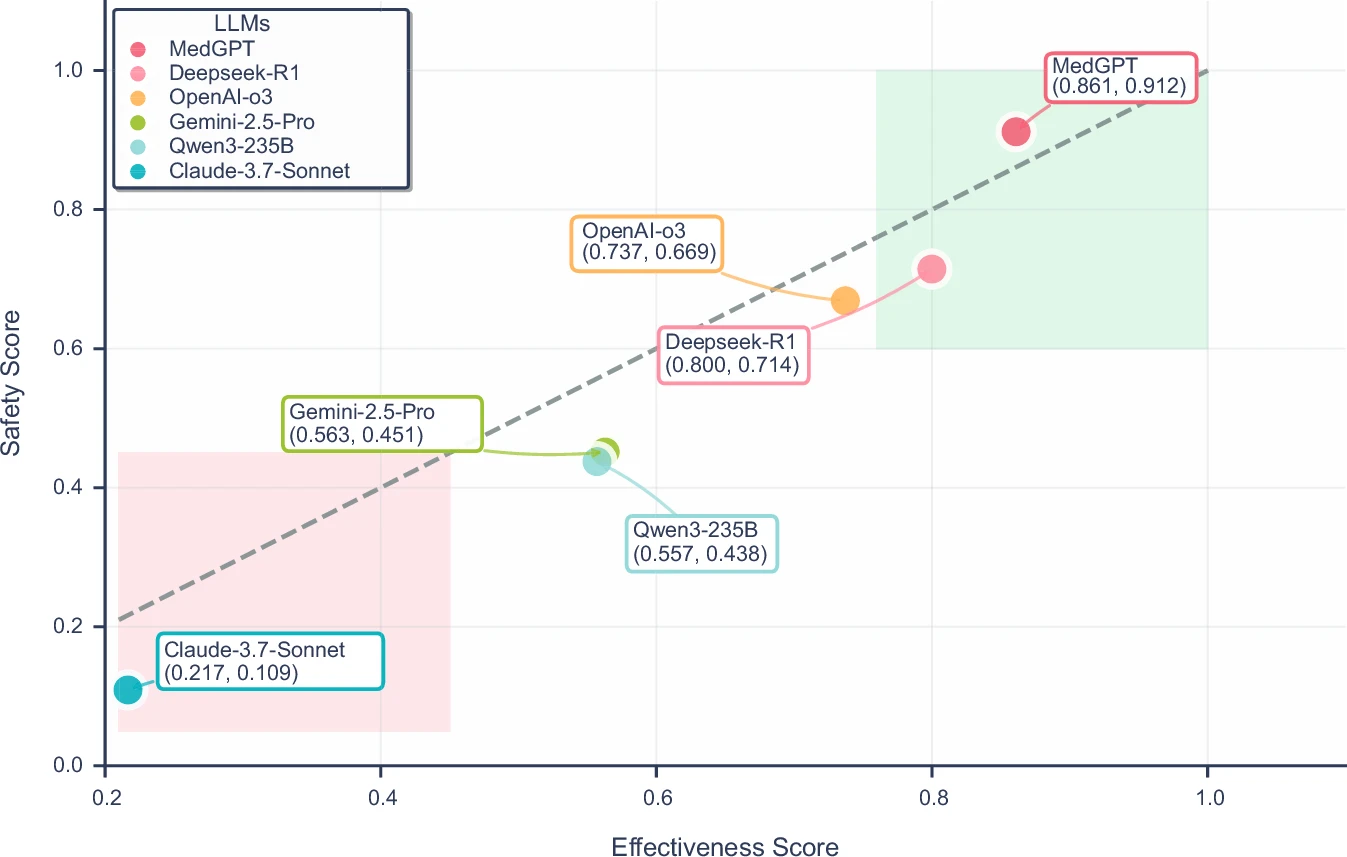
Nei test sistematici condotti sui principali modelli globali utilizzando questo benchmark, MedGPT – sviluppato appunto dall’azienda cinese di tecnologia medica Future Doctor – ha ottenuto i punteggi più alti in tutte le metriche. Nel confronto sono stati inclusi i principali modelli internazionali, tra cui DeepSeek-R1, OpenAI o3, Gemini 2.5, Qwen3-235B e Claude 3.7.
Un dato rilevante è che, mentre molti modelli hanno mostrato prestazioni più deboli sul fronte della sicurezza, MedGPT è stato l’unico a ottenere un punteggio di sicurezza superiore a quello di efficacia, segnale di una cautela clinica ritenuta essenziale in ambito sanitario.
Un’IA progettata per “pensare come un medico”
Le performance di MedGPT derivano dall’impostazione originaria di Future Doctor: fin dall’inizio sicurezza ed efficacia, basate sul consenso degli esperti clinici, sono state integrate nell’architettura del sistema, dichiarano. L’obiettivo era creare un’IA che “pensi come un medico” modellando il ragionamento sulla cognizione umana più che sull’addestramento massivo dei dati.
Già nel 2023 MedGPT aveva mostrato forte adattabilità clinica in sperimentazioni con pazienti reali, raggiungendo il 96% di concordanza diagnostica con i medici curanti in ospedali di terzo livello. Oggi oltre 10.000 medici utilizzano la piattaforma Future Doctor, generando circa 20.000 feedback clinici reali ogni settimana. Grazie a questo meccanismo di “iterazione guidata dal feedback”, l’accuratezza del sistema cresce dell’1,2–1,5% al mese.
Per approfondire.
Decisioni automatizzate, vite reali. Nella sanità del futuro, siamo ancora noi a decidere?
L’impatto del Covid-19 sulla salute mentale. Torna Data Analysis
Gli stereotipi di genere nel parlamento italiano, da De Gasperi ai giorni nostri #DataAnalysis
Votare per o votare contro. Il pericolo del partyism in politica (in Italia e negli Stati Uniti)
Come si misura la solitudine e la felicità
“Quando nella scienza non ci sono dati allora è pubblicità”
Riaprono le discoteche. Dopo mesi di sofferenza e anni di bilancio in rosso #DataAnalysis

{kind=link}
{kind=link}