Reclutare partecipanti è sempre stata una sfida cruciale per gli studi in scienze sociali e comportamentali. Questionari, esperimenti psicologici e sondaggi richiedono tempo, risorse e, spesso, una buona dose di fortuna per trovare soggetti disponibili e rappresentativi. È in questo contesto che l’intelligenza artificiale si propone come una soluzione innovativa: creare partecipanti virtuali, capaci di rispondere come esseri umani.
Questi tentativi anzitutto già esistono, e promettono di semplificare la ricerca, simulando risposte comportamentali e psicologiche senza dover reclutare fisicamente persone. Per molti ricercatori, l’idea è allettante, ed è proprio questo fascino a rendere urgente il dibattito metodologico e etico: prima che l’uso diventi diffuso, è fondamentale capire i rischi e le regole di buona pratica.
È evidente che la comunità scientifica è spaccata su questo fronte, come emerge dalle letture contrastanti che emergono dai molti lavori che si stanno pubblicando in questi ultimi mesi.
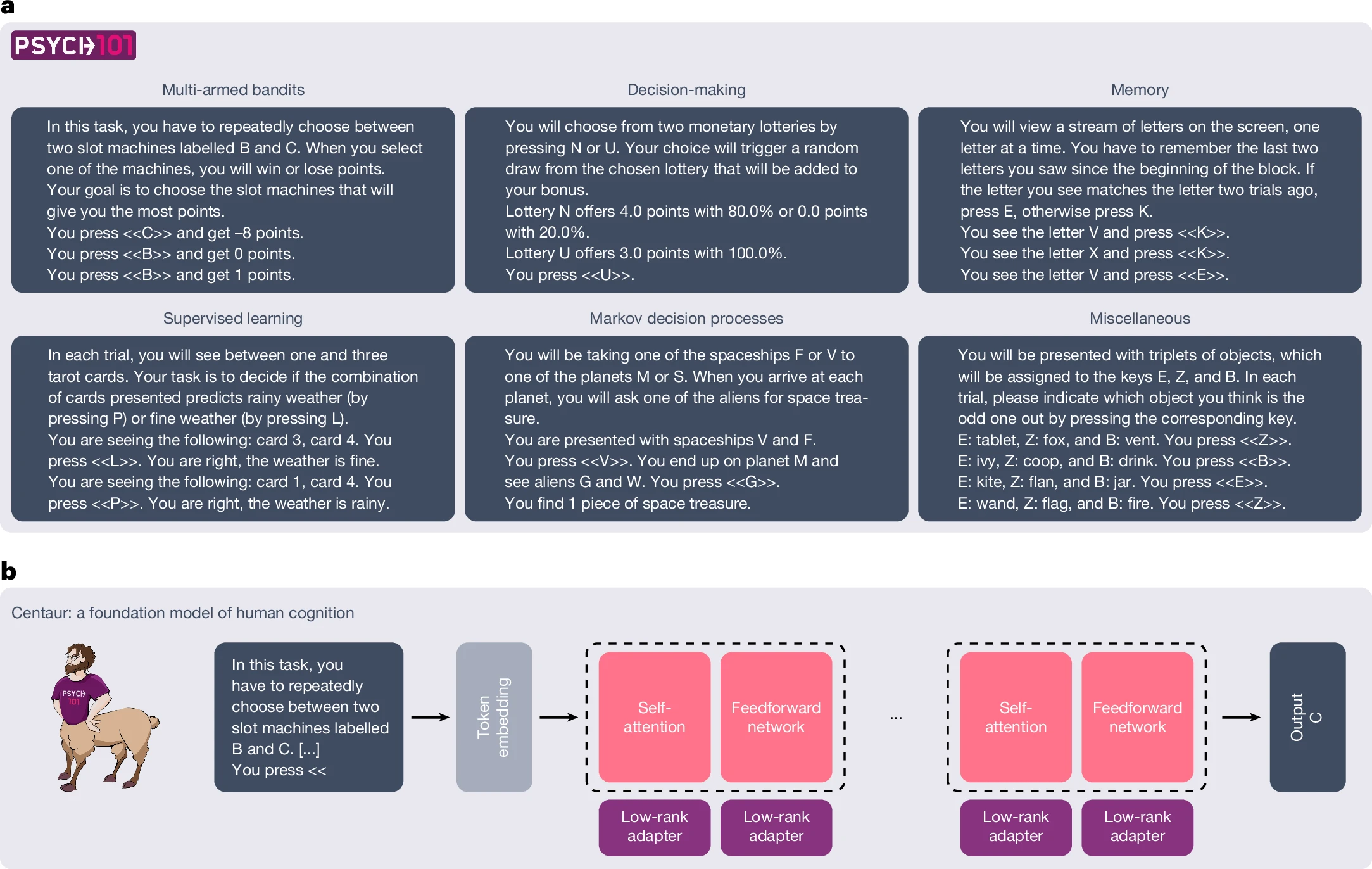
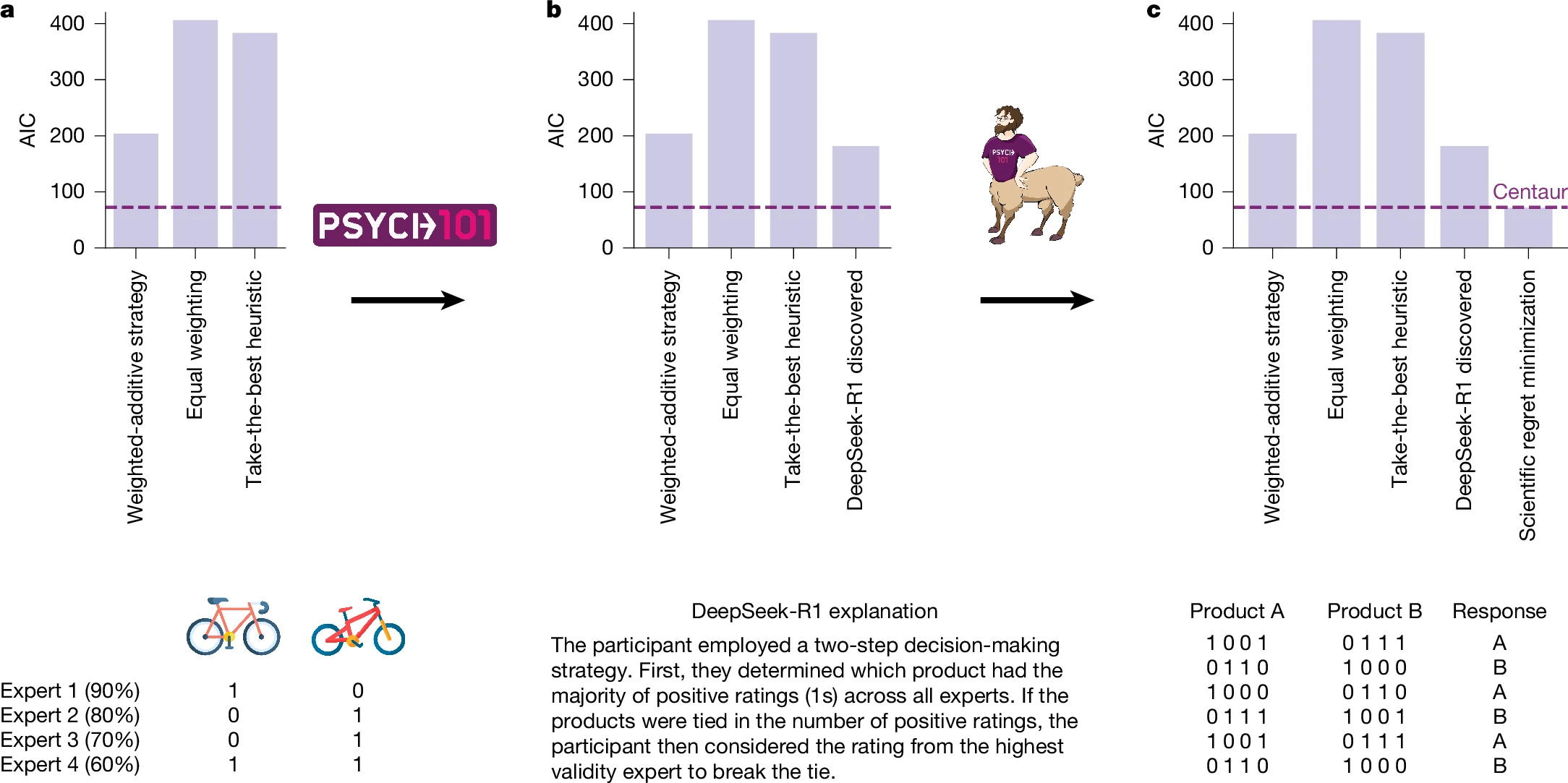
A luglio Nature ha pubblicato i risultati di Centaur, un modello sviluppato per predire comportamenti in esperimenti esprimibili in linguaggio naturale. Centaur è stato derivato addestrando un modello linguistico all’avanguardia su un dataset di grande scala chiamato Psych-101, che include dati dettagliati di oltre 60.000 partecipanti e più di 10 milioni di scelte in 160 esperimenti. Centaur non solo cattura meglio il comportamento dei partecipanti “tenuti fuori” rispetto ai modelli cognitivi esistenti, ma generalizza anche a contesti nuovi, modifiche strutturali dei task e domini completamente diversi. Inoltre, le rappresentazioni interne del modello diventano più allineate con l’attività neurale umana dopo il fine-tuning. Questo dimostra che è possibile costruire modelli computazionali in grado di simulare il comportamento umano in modo più coerente e fedele rispetto ai tradizionali campioni virtuali.
Non tutti gli studi condividono questo ottimismo. Una recente ricerca apparsa solo in preprint ad agosto 2025, ha esaminato l’affidabilità dei LLM, inclusi modelli avanzati come Centaur, nel simulare risposte psicologiche umane. Gli autori mettono in guardia contro l’uso di LLM come sostituti dei partecipanti reali: anche leggere variazioni nel linguaggio, che modificano il significato delle domande, producono discrepanze significative tra risposte umane e risposte dei modelli.
Inoltre, diversi modelli LLM rispondono in modo molto diverso a nuovi stimoli, evidenziando una mancanza di affidabilità generale. La conclusione dello studio è chiara: i LLM non simulano la psicologia umana in modo attendibile e vanno considerati strumenti utili ma fondamentalmente inaffidabili, da validare sempre confrontandoli con risposte di partecipanti reali per ogni nuova applicazione.
Questo punto sottolinea un limite importante dei campioni virtuali e dei modelli computazionali: anche se Centaur e simili possono fornire risultati impressionanti su dataset già noti, la loro generalizzabilità e affidabilità in contesti realmente nuovi rimane incerta.
Le stesse cautele sono emerse da nuovo studio pubblicato in preprint su arXiv a settembre 2025 e ripreso nientemeno che su Science. L’autore è Jamie Cummins, scienziato dell’Università di Berna, che ha analizzato quanto le scelte dei ricercatori — dal modello linguistico di grande dimensione (LLM) utilizzato, alle impostazioni, ai dati demografici forniti al modello — possano influenzare i risultati. Lo studio sottolinea un punto fondamentale: non esiste una “combinazione perfetta” di parametri che produca risultati affidabili e coerenti con i dati umani.
Per testare l’effetto delle scelte dei ricercatori, Cummins ha variato diversi elementi e le possibili combinazioni sono arrivate a 252 configurazioni differenti, ognuna delle quali poteva produrre risultati diversi.
I risultati ottenuti dai modelli sono stati confrontati con quelli reali dei partecipanti umani, valutando la somiglianza delle distribuzioni dei punteggi, la capacità dei modelli di identificare i partecipanti con i punteggi più alti e la coerenza delle correlazioni tra le due misure psicologiche. L’esito è stato chiaro: le variabili metodologiche producono una variabilità ampissima. Alcune configurazioni riproducevano meglio le classifiche dei partecipanti, altre la correlazione tra le misure psicologiche, ma nessuna combinazione funzionava in modo affidabile su tutti i fronti. Due ricercatori, usando scelte entrambe metodologicamente difendibili, potrebbero ottenere risultati opposti e trarre conclusioni divergenti.
Rischi scientifici ed etici
Affidarsi ai modelli per simulare risposte di gruppi vulnerabili — anziani, minoranze, persone residenti in Paesi lontani dai contesti occidentali più rappresentati nei dati di training — può produrre risultati fuorvianti o addirittura dannosi, spiega Cummings. Questi gruppi sono spesso sottorappresentati nei dati di addestramento dei modelli, e affidarsi a simulazioni può rischiare di escluderli ulteriormente, compromettendo la rappresentatività e la fiducia nella scienza.
Anche sul piano scientifico, il rischio è che l’uso dei campioni virtuali dia l’illusione di rigore e affidabilità. Alcuni studi potrebbero basarsi esclusivamente su dati generati dall’IA senza verificare la coerenza con risposte umane reali, con conseguenze potenzialmente gravi per la replicabilità e la validità dei risultati.
Opportunità, limiti e possibili applicazioni
Nonostante i rischi, questo approccio ha comunque un potenziale significativo per test preliminari, simulazioni esplorative, o per ottimizzare questionari prima di coinvolgere partecipanti reali. La chiave sta nella consapevolezza metodologica: comprendere quanto ogni scelta — modello, prompt, impostazioni — possa influenzare i risultati.
Il dibattito è appena iniziato. La comunità scientifica non ha ancora definito linee guida etiche o metodologiche sull’uso dei campioni virtuali né discusso a fondo le situazioni in cui il loro impiego sia appropriato. La ricerca invita a riflettere non solo sulla validità dei dati, ma anche sulle implicazioni sociali ed etiche, prima che la tecnologia venga adottata su larga scala.
Per approfondire.
L’intelligenza artificiale può aiutare la ricerca scientifica? Forse anche troppo


{kind=link}
{kind=link}