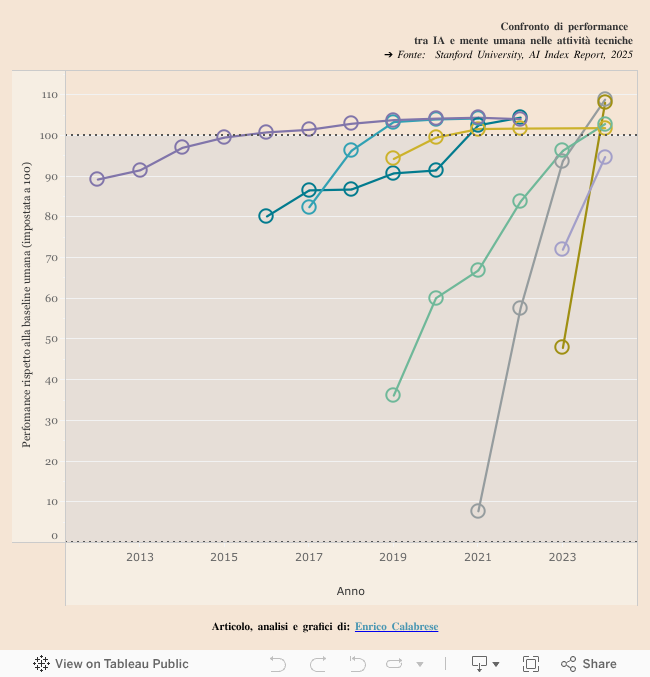
Il divario tra il ragionamento umano e quello dei chatbot si sta riducendo, e in fretta. Nell’ultimo anno, come evidenziato dalla Stanford University nello studio Artificial Intelligence Index Report 2025, i sistemi di intelligenza artificiale hanno continuato a registrare rapidi progressi, superando le prestazioni umane in compiti tecnici in cui prima non erano all’altezza, come la matematica avanzata e il ragionamento visivo. Ma cos’altro ci può dire lo studio? E com’è stata effettuata l’analisi?
I ricercatori dell’Università californiana hanno preso in considerazione diversi compiti di carattere tecnico impostando al 100% il parametro di riferimento umano. In seguito, per confrontare le prestazioni dei sistemi di AI, hanno sviluppando una percentuale di performance che, da quanto registrato nel report, nel corso degli anni ha continuato a ridurre il divario con l’operatività umana. Le attività prese in considerazione per lo studio sono in tutto otto e riguardano processi come la classificazione delle immagini, comprensione e ragionamento multimodale, ragionamento visivo e altro ancora. Ma su quali compiti i modelli di AI riescono a performare meglio degli esseri umani? E in quali meno?
Da ChatGPT a Gemini, molti dei principali modelli di IA stanno rapidamente dimostrando di poter superare la soglia operativa umana, soprattutto in una serie di compiti tecnici. L’unica attività in cui i sistemi di IA non hanno ancora raggiunto gli esseri umani è la comprensione e il ragionamento multimodale, che comporta l’elaborazione e il ragionamento in più formati, come immagini, grafici e diagrammi. Tuttavia, secondo quanto riportato nello studio, vedere accorciare il divario tecnico su questi parametri è solo una questione di tempo.
Nel 2024, il modello o1 di OpenAI ha ottenuto un punteggio del 78,2% in MMMU, e cioè un benchmark che valuta i sistemi su compiti multidisciplinari che richiedono conoscenze di livello universitario. Questo punteggio è stato di soli 4,4 punti percentuali inferiore al valore di riferimento umano, pari all’82,6%. Inoltre, il modello venuto fuori dai laboratori di ricerca del CEO Sam Altman, ha anche uno dei tassi di “allucinazione” più bassi tra tutti i modelli di intelligenza artificiale. Questo valore fa riferimento a un fenomeno che, secondo quanto descritto da IBM, avviene nel momento in cui un modello linguistico di grandi dimensioni (LLM) – come una chatbot di intelligenza artificiale generativa o uno strumento di visione computerizzata – rileva elementi o oggetti che non esistono o che sono impercettibili per gli esseri umani, portando a risultati imprecisi o senza senso.
Tutto ciò è un notevole balzo in avanti rispetto alla fine del 2023, quando Google Gemini aveva ottenuto solo il 59,4%, evidenziando il rapido miglioramento delle prestazioni dell’IA in questi compiti tecnici. Un futuro promettente e che sarà interessante analizzare in ogni passo della sua velocissima evoluzione.
Per approfondire.
Quanto sono efficaci le molecole scoperte con l’intelligenza artificiali nei trial clinici?
Come cambia la ricerca di informazioni sul web nell’era dell’intelligenza artificiale generativa?